ConcurrentHashMap
概述
ConcurrentHashMap 是 Java 中一个线程安全的哈希表实现,广泛应用于并发编程中。它位于 java.util.concurrent 包中,允许多个线程并发访问,并且提供高效的读写操作,避免了传统的 Hashtable 或者 HashMap 在并发访问时可能出现的性能瓶颈。
ConcurrentHashMap 特点:
- 分段锁:在 JDK 1.7 及之前版本中,
ConcurrentHashMap采用了分段锁(Segment Locking)机制,整个哈希表被分为多个段,每个段拥有独立的锁。这样,在不同段上的操作不会互相干扰,提高了并发性能。每个段的大小为固定的大小,所以ConcurrentHashMap在进行插入或查找时,能确保只有对同一段的操作会发生竞争,而不会影响其他段。 - 无锁优化:从 JDK 1.8 开始,
ConcurrentHashMap采用了更加精细化的锁机制(如:CAS、synchronized 和 bin 锁等),避免了 JDK 1.7 中分段锁的性能开销,同时提高了并发性。 - 安全的线程操作:
ConcurrentHashMap提供了线程安全的put、get、remove等方法,支持高并发环境下的操作。 - 强一致性:它保证了
get操作的线程安全,保证了数据的强一致性,但put和remove操作可能会影响其他线程的访问。
ConcurrentHashMap 1.7
数据结构
Java 7 中ConcurrnetHashMap 由很多个 Segment 数组组合,每一个 Segment 指向一个 HashEntry 对象的数组,一个类似于 HashMap 的结构,类似于链表的结构。所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦 初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发
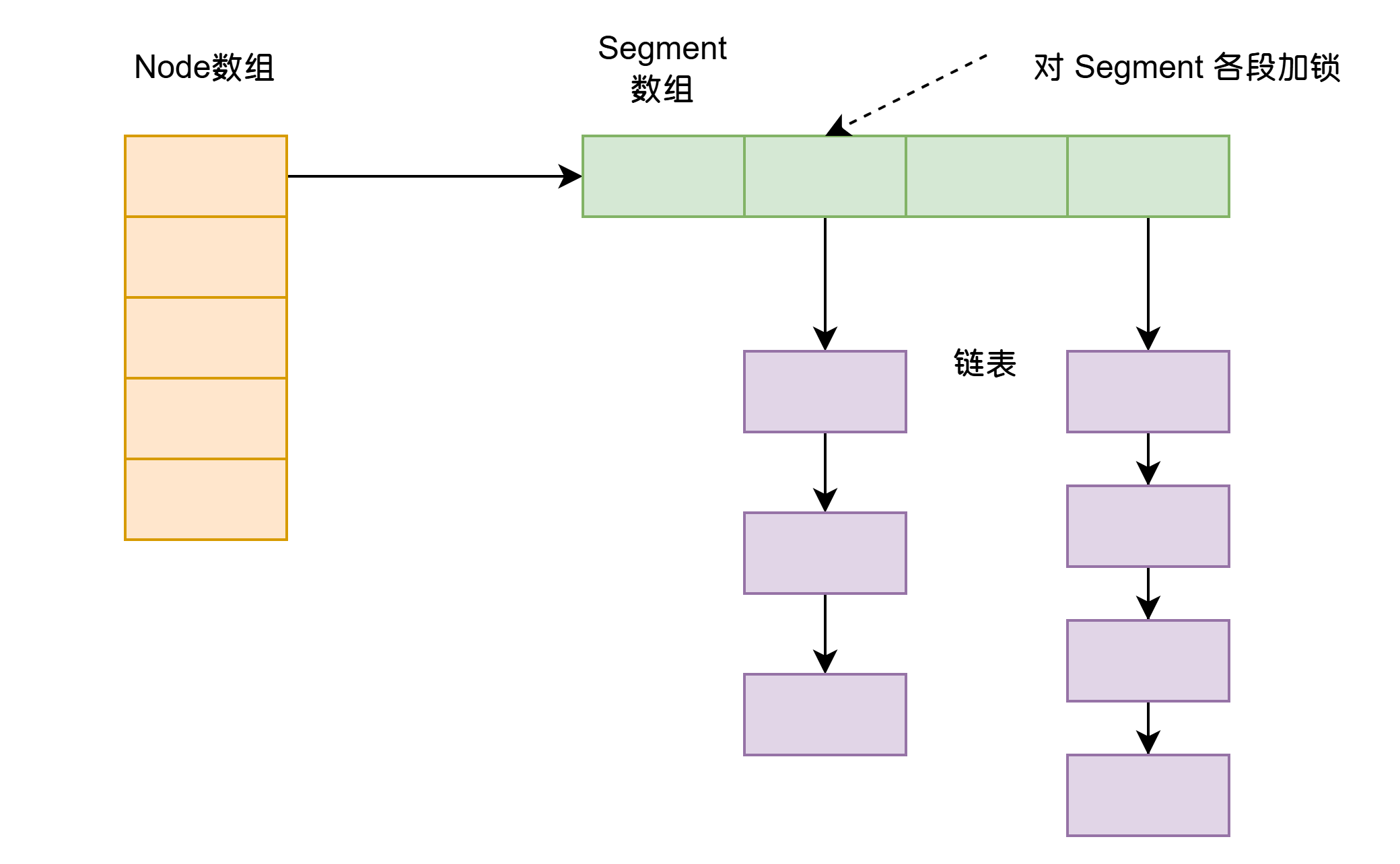
初始化
通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
- 初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
- 比如你初始容量是 64,Segment **的容量为**16,那么每个段中哈希表的初始容量就为 64/16=4。
// 默认初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 默认并发级别
static final int DEFAULT_CONCURRENCY_LEVEL = 16;接着看下这个有参构造函数的内部实现逻辑。
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// 参数校验
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 校验并发级别大小,大于 1<<16,重置为 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// 2的多少次方
int sshift = 0;
int ssize = 1;
// 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 记录段偏移量
this.segmentShift = 32 - sshift;
// 记录段掩码
this.segmentMask = ssize - 1;
// 设置容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//Segment 中的类似于 HashMap 的容量至少是2或者2的倍数
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 创建 Segment 数组,设置 segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}总结一下在 Java 7 中 ConcurrentHashMap 的初始化逻辑。
- 必要参数校验——初始化容量、负载因子、并发级别若小于 0,则抛出参数检验异常
- 校验并发级别
concurrencyLevel大小,如果大于最大值,重置为最大值。无参构造默认值是 16. - 寻找并发级别
concurrencyLevel之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。 - 记录
segmentShift偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28. - 记录
segmentMask,默认是 ssize - 1 = 16 -1 = 15. - 初始化
segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容 - ConcurrentHashMap 初始化的时候会初始化 第一个桶 segment[0] ;对于其他桶来说,在插入第一个值的时候进行初始化。
put 流程
put(key,value)流程
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
// 其实也就是把高4位与segmentMask(1111)做与运算
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 如果查找到的 Segment 为空,初始化
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 判断 u 位置的 Segment 是否为null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// 获取0号 segment 里的 HashEntry<K,V> 初始化长度
int cap = proto.table.length;
// 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
float lf = proto.loadFactor;
// 计算扩容阀值
int threshold = (int)(cap * lf);
// 创建一个 cap 容量的 HashEntry 数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 自旋检查 u 位置的 Segment 是否为null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS 赋值,只会成功一次
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
计算要 put 的 key 的位置,获取指定位置的
Segment。如果指定位置的
Segment为空,则初始化这个Segment.初始化 Segment 流程:
- 检查计算得到的位置的
Segment是否为 null. - 为 null 继续初始化,使用
Segment[0]的容量和负载因子创建一个HashEntry数组。 - 再次检查计算得到的指定位置的
Segment是否为 null. - 使用创建的
HashEntry数组初始化这个 Segment. - 自旋判断计算得到的指定位置的
Segment是否为 null,使用 CAS 在这个位置赋值为Segment.
- 检查计算得到的位置的
Segment.put插入 key,value 值。
put(key,value)
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 计算要put的数据位置
int index = (tab.length - 1) & hash;
// CAS 获取 index 坐标的值,并查找该index位置的HashEntry元素
HashEntry<K,V> first = entryAt(tab, index);
//遍历该HashEntry元素的链表
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
//该位置为空
else {
// first 有值没说明 index 位置已经有值了,有冲突,链表头插法。
// 再次判断该hashEntry位置是否为空
if (node != null)
//不为空
//头插法
node.setNext(first);
else
//创建新节点
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 容量大于扩容阀值,小于最大容量,进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
tryLock()获取锁,获取不到使用scanAndLockForPut方法继续获取。计算 put 的数据要放入的 index 位置(HashEntry 数组),然后获取这个位置上的
HashEntry。遍历该位置的 HashEntry,因为这里获取的
HashEntry可能是一个空元素数组,也可能是链表已存在,所以要区别对待。在目标槽位处,通过CAS(CompareAnd swap)操作尝试将新节点插入到链表头部
如果 槽位不为空,已经有节点存在,进入链表或树的插入逻辑:
遍历链表或树,寻找合适的位置(相同 hash 值和 equals 相等的 key 存在的位置)。
若找到已有键值对,替换原有值(根据 onlylfAbsent 参数决定是否替换)。
若未找到相同键值对,则使用 CAS 或 synchronized 添加新节点至链表
如果 槽位为空,则直接尝试 CAS 插入新节点。
在插入新元素时候(除了替换原有的元素之外)如果当前容量大于扩容阀值,小于最大容量,进行扩容,扩容后再进行插入操作
自旋获取 hash 位置的 HashEntry
不断的自旋 tryLock() 获取锁。当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 自旋获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// 自旋达到指定次数后,阻塞等到只到获取到锁
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}Rehash 扩容
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize参数里 的 node 会在扩容之后使用链表头插法 插入到指定位置。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
// 老容量
int oldCapacity = oldTable.length;
// 新容量,扩大两倍
int newCapacity = oldCapacity << 1;
// 新的扩容阀值
threshold = (int)(newCapacity * loadFactor);
// 创建新的数组
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,默认2扩容后是4,-1是3,二进制就是11。
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
// 遍历老数组
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// 如果当前位置还不是链表,只是一个元素,直接赋值
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果是链表了
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 新的位置只可能是不便或者是老的位置+老的容量。
// 遍历结束后,lastRun 后面的元素位置都是相同的
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
// 遍历剩余元素,头插法到指定 k 位置。
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 头插法插入新的节点
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}ConcurrentHashMap 1.8
数据结构
JDK1.8 版本的底层是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。锁粒度进一步减小,1.7 是锁 segment 数组,1.8 是锁 node 数组
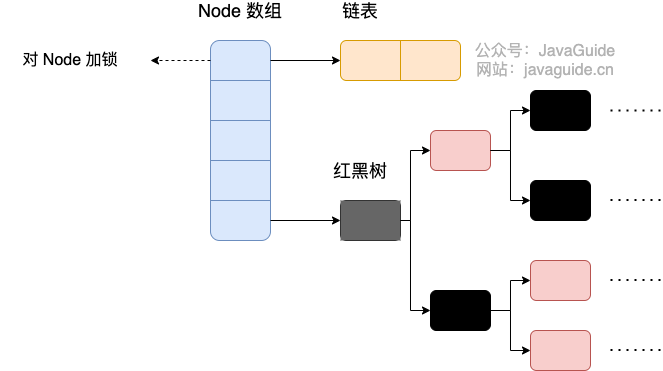
初始化
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。
if ((sc = sizeCtl) < 0)
// 让出 CPU 使用权
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl (sizeControl 的缩写),它的值决定着当前的初始化状态。
- -1 说明正在初始化,其他线程需要自旋等待
- -N 说明 table 正在进行扩容,高 16 位表示扩容的标识戳,低 16 位减 1 为正在进行扩容的线程数
- 0 表示 table 初始化大小,如果 table 没有初始化
- >0 表示 table 扩容的阈值,如果 table 已经初始化
put 流程
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}总结:
- 根据 key 计算出 hashcode ,并判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树
小结
在 jdk1.8 之前采用分段锁保证线程安全,默认情况下,concurrenthashmap 将 hash 表分为 16 个分片,在加锁的时候,会针对每个单独的分片进行加锁,其它分片不受影响。这种方式通过减少锁的竞争,来提高并发度
在 jdk8 以及以上版本,采用了更细粒度的锁机制:CAS + synchronized。在进行简单的比如插入,更新操作时,会使用 cas 来保证线程安全,避免了加锁开销;对于复杂的操作比如链表转红黑树时,使用 sychronized 只锁住 node 数组头节点。这种方式锁定粒度更细,从而能大大提高并发度。
JDK1.8 为什么使用内置锁 synchronized 来代替重入锁 ReentrantLock,原因如下:
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized 的性能并不比 ReentrantLock 差,在粗粒度加锁中 ReentrantLock 可能通过 Condition 来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition 的优势就没有了
- JVM 的开发团队从来都没有放弃 synchronized,而且基于 JVM 的 synchronized 优化空间更大,使用内嵌的关键字比使用 API 更加自然
- 在大量的数据操作下,对于 JVM 的内存压力,基于 API 的 ReentrantLock 会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
版权所有
版权归属: